Bert
Bert大家应该知道,就是Google的《BERT: Pre-training of Deep Bidirectional Transformers forLanguage Understanding》这篇文章,Google凭借这篇文章刷了很多榜,并且发布了中文和多语言的与训练模型,使得没有太高算力的小公司也可以用这个与训练模型实现比较大的提升;现在Bert在工业界算是应用比较多了。
AoA
之前看SQuAD发现有一个BERT + DAE + AoA,一直没有找到AoA是什么意思,前几天在知乎的一篇文章上面发现AoA是Attention-over-Attention的缩写,Google一下找到了另一个知乎的文章和Attention-over-Attention Neural Networks for Reading Comprehension这篇论文,知乎的文章不说了,介绍的不是特别详细没看懂,所以直接看了论文。
那么AoA到底是什么东西,简单的说就是下面这张图:
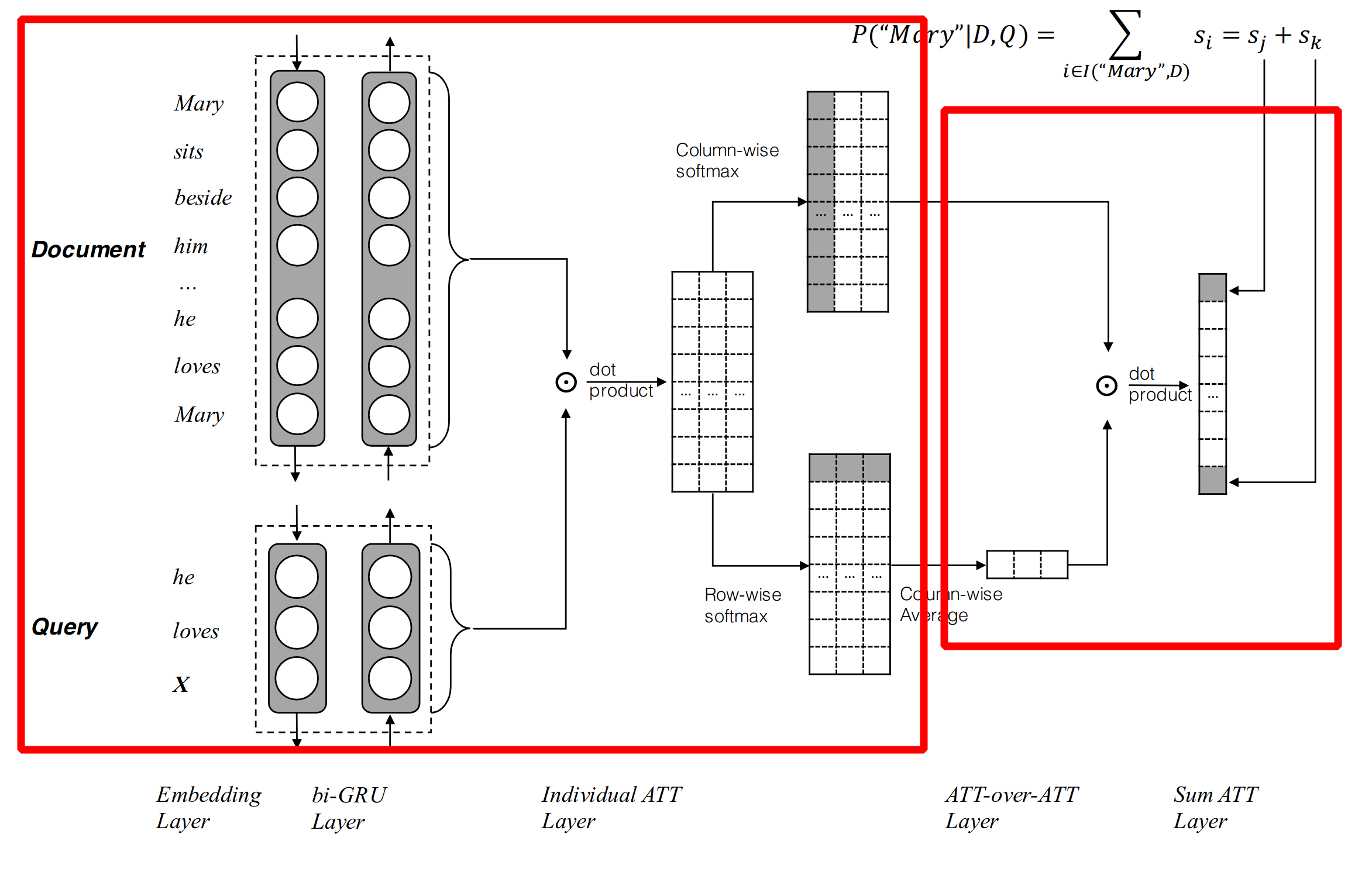
我们先看左边红框的部分(图是论文里边的,框是我画的)。
输入就是两个Tensor,一个Document一个是Query,为什么有两列,是因为论文中AoA这层前面接的是一个双向的RNN,两列分别是正向和反向RNN的隐藏状态。
然后就是Document和Query点积得到一个相似度矩阵,这个矩阵大小是D乘Q,M的每一列是Document的每一个词,每一行是Query的每一个词,矩阵的每一项在论文中叫Pair-wise Matching Score:
接下来就是重点了,如图,分别对列、行进行softmax,得到了query-to-document attention和document-to-query attention;
对列softmax,query-to-document attention
对于Query中每一个时刻t的词,将这一列的score取softmax,也就是这个Query中当前这个词,对Document中每一个词关注的概率:
对行softmax,document-to-query attention
对称的,对于Document中每一个时刻t的词,将这一行的score取softmax,也就是这个Document中当前词,对Query中每一个词关注的概率:
对比Attention Is All You Need
Attention Is All You Need中,的注意力公式是:
这个在论文中叫Scaled Dot-Product Attention,如果去掉Scaled和V,就变成了:
和上面的query-to-document attention、document-to-query attention其中一个是一样的;至于和哪个一样的,如果我们把K换做用D表示,而且softmax默认的维度是-1,也就是D;这样这个公式和上面的query-to-document attention就是一样的。
也就是说,Attention Is All You Need、Transformer、Bert这些模型都只有 query-to-document* attention
Attention over attention
上面图中右边的红框,是模型分成两个Attention之后的处理,直接把document-to-query attention在列上取了平均值,每一列是一个Document,相当于是对Document中每一个单词,对Query的attention取了平均数,也就是整个文档对Query中每一个词的Attention;大小是Q。
然后用,query-to-document attention和上面的整个文档对Query的Attention相乘,得到最终的“attended document-level attention”,这个相当于Query中每一个词,对Document的query-to-document attention,不是直接取平均数,而是根据整个文档对Query中每个词的Attention来计算一个加权平均数。
AoA有没有用
Ensemble BERT with Data Augmentation andLinguistic Knowledge on SQuAD 2.0这篇论文试图在Bert的最后一个隐藏层中加上AoA,可到的结果是:
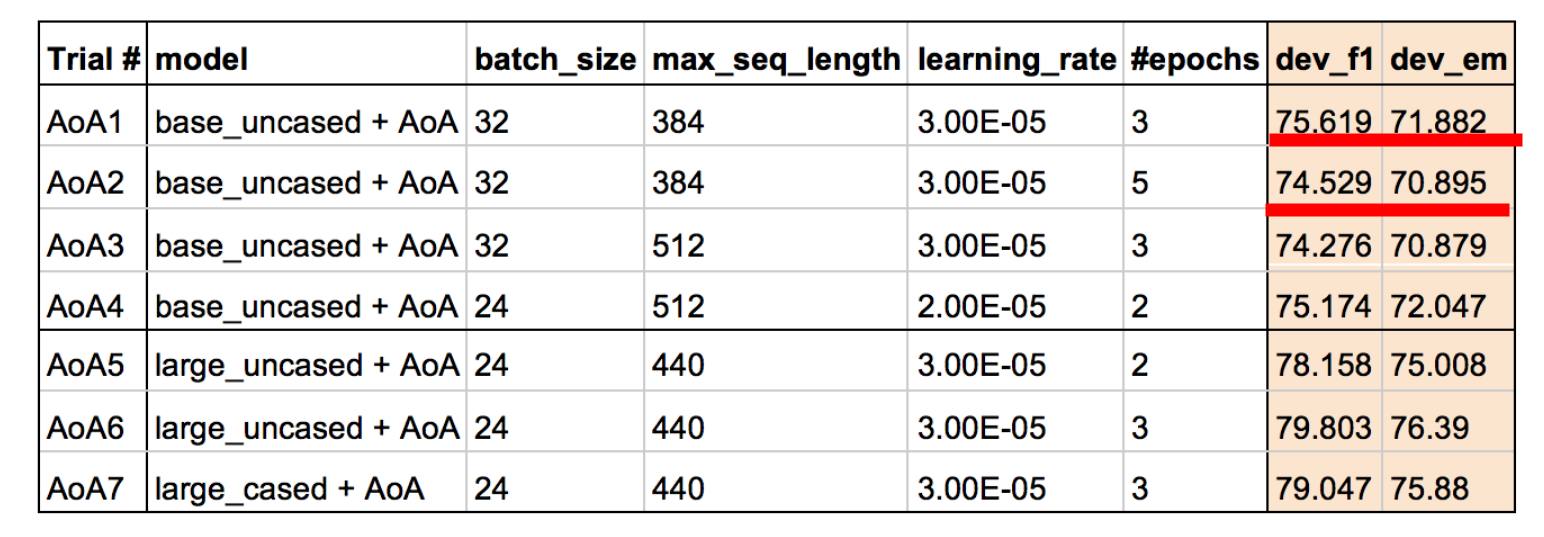
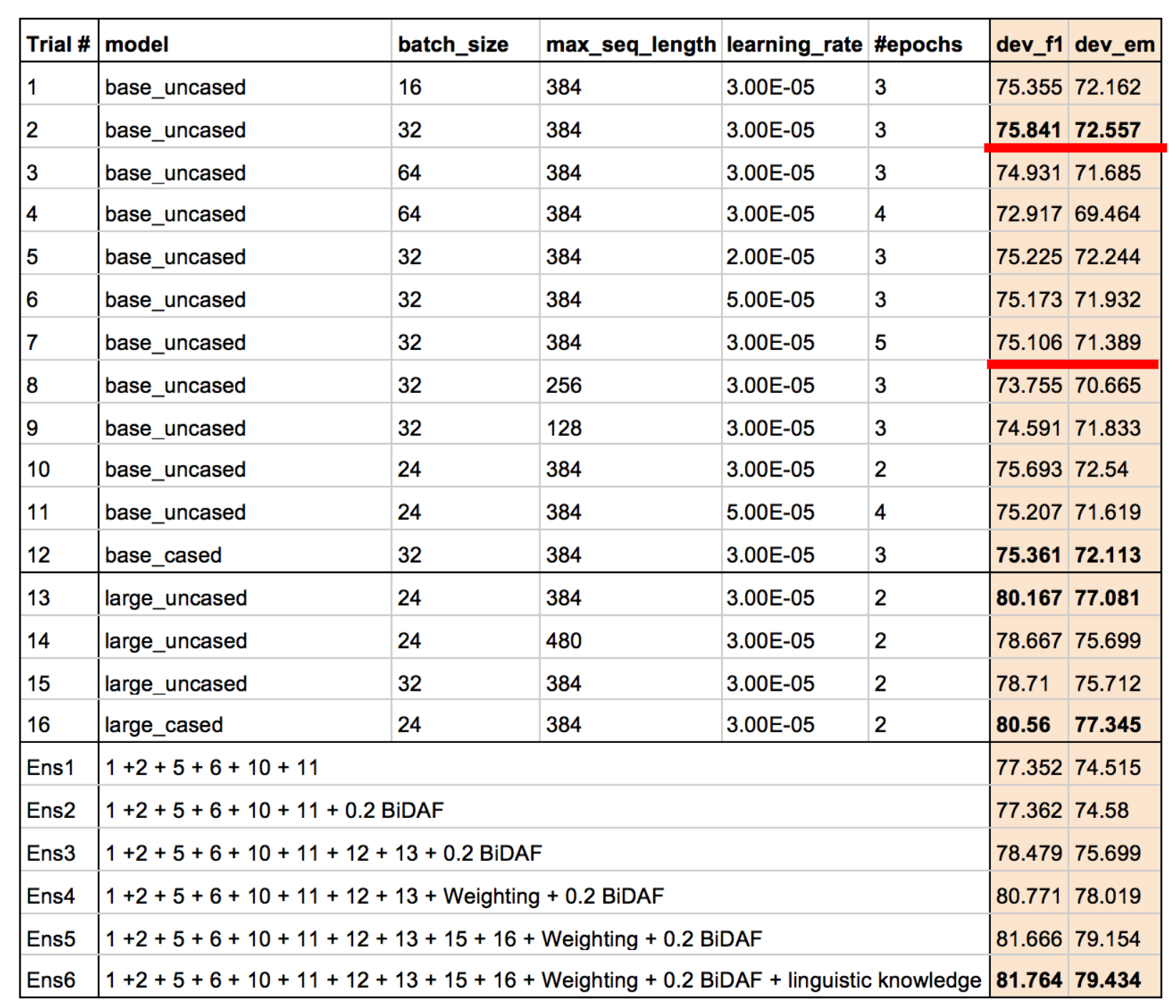
可以看到,能够形成比较的有两组结果,都是加上AoA后f1和em反而降低,说明了这两组超参数上,Bert加AoA是没有用的。
论文中写到:“However, we found that adding AoA did not improve the performance ofBERT. We thought this is because the BERT Transformer already uses bidirectional self-attention, sono additional attention is needed for BERT.”;他们尝试了几次AoA没有提升后就放弃了,至于AoA到底有没有用,最好在更多的超参数上再做一下实验。
Bert加AoA为什么没有提升:上面论文的观点是,Bert没有AoA但是Bert的输入是两个句子的拼接做self attention,相当于query to document和document to query已经都有了。
原来以为Bert是简单粗暴,现在看还是比较巧妙的。